| timestamp | group | val | |
|---|---|---|---|
| 1 | 2020-04-02 | 18 | 8 |
| 2 | 2020-04-03 | 18 | 6 |
| 7 | 2020-04-08 | 17 | 2 |
| 8 | 2020-04-09 | 20 | 4 |
| 9 | 2020-04-10 | 19 | 5 |
| ... | ... | ... | ... |
| 94 | 2020-07-04 | 21 | 6 |
| 96 | 2020-07-06 | 18 | 6 |
| 97 | 2020-07-07 | 20 | 6 |
| 98 | 2020-07-08 | 18 | 7 |
| 99 | 2020-07-09 | 22 | 8 |
こういうデータがあり(作成コードは後述)、group, value毎に数え上げると次のようになるとする。
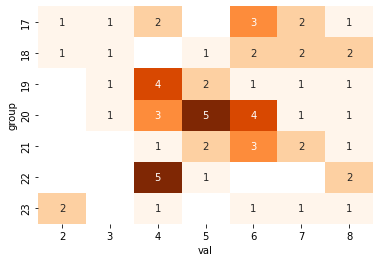
このデータについて、group毎に、valueが閾値(threshold)以上のデータが何個あるという表を作りたいとする。
期待結果は次のようなものである。
| threshold | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| group | |||||||
| 17 | 10 | 9 | 8 | 6 | 6 | 3 | 1 |
| 18 | 9 | 8 | 7 | 7 | 6 | 4 | 2 |
| 19 | 10 | 10 | 9 | 5 | 3 | 2 | 1 |
| 20 | 15 | 15 | 14 | 11 | 6 | 2 | 1 |
| 21 | 9 | 9 | 9 | 8 | 6 | 3 | 1 |
| 22 | 8 | 8 | 8 | 3 | 2 | 2 | 2 |
| 23 | 6 | 4 | 4 | 3 | 3 | 2 | 1 |
とりあえず、試しに
grouped = df.groupby('group')['value']
grouped.agg([
lambda x: sum(x>=5),
lambda x: sum(x>=6),
lambda x: sum(x>=7),
])
| <lambda_0> | <lambda_1> | <lambda_2> | |
|---|---|---|---|
| group | |||
| 17 | 6 | 6 | 3 |
| 18 | 7 | 6 | 4 |
| 19 | 5 | 3 | 2 |
| 20 | 11 | 6 | 2 |
| 21 | 8 | 6 | 3 |
| 22 | 3 | 2 | 2 |
| 23 | 3 | 3 | 2 |
列名はLambda関数の名前だそうで、次のようにlambda関数の__name__を書き換えると変えられるらしいことがわかった。 ●コード例1
# Successful trial 1
def makef(i):
f = lambda x: sum(x >= i)
f.__name__ = '%d' % i
return f
df.groupby('group')['value'].agg([
makef(i) for i in range(df['value'].min(), df['value'].max() + 1)
])
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|
| group | |||||||
| 17 | 10 | 9 | 8 | 6 | 6 | 3 | 1 |
| 18 | 9 | 8 | 7 | 7 | 6 | 4 | 2 |
| 19 | 10 | 10 | 9 | 5 | 3 | 2 | 1 |
| 20 | 15 | 15 | 14 | 11 | 6 | 2 | 1 |
| 21 | 9 | 9 | 9 | 8 | 6 | 3 | 1 |
| 22 | 8 | 8 | 8 | 3 | 2 | 2 | 2 |
| 23 | 6 | 4 | 4 | 3 | 3 | 2 | 1 |
望み通りの結果が得られたのだが、このやり方だと列名が文字列型になってしまうのが残念である。
という訳で、次のようにして列名を後で書き換えるようにしたら、うまく動かなかった。
# Failed trial
columns = range(df['value'].min(), df['value'].max() + 1)
result = df.groupby('group')['value'].agg([
lambda x: sum(x >= i) for i in columns
])
result.columns = columns
result
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|
| group | |||||||
| 17 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 18 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 19 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 20 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 21 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 22 | 2 | 2 | 2 | 2 | 2 | 2 | 2 |
| 23 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
全ての列が最後の列と同じになっている。
原因はPythonの"late binding closure"(dynamic scoping)で、このページに酷似した例の解説があるが、[lambda x: sum(x >= i) for i in columns]のiがlambda関数のローカル変数でなくその外側のforループのスコープの変数で、全てのlambda関数のiがforループが終わった時点のiになるからだった。
他の例として、例えば
lambdas = [lambda: i for i in range(5)]
[f() for f in lambdas]
lambda : i がループ終了後のiを参照し、
となる。ループ中のiを使いたいなら、[4, 4, 4, 4, 4]
lambda i=i: のようにしてローカル変数に保存するのが定跡らしく、
lambdas = [lambda i=i: i for i in range(5)]
[f() for f in lambdas]
という結果になる。[0, 1, 2, 3, 4]
従って、次のようにした。
●コード例2
# Successful trial 2
columns = range(df['value'].min(), df['value'].max() + 1)
result = df.groupby('group')['value'].agg([
lambda x, i=i: sum(x>=i) for i in columns
])
result.columns = columns
result
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
|---|---|---|---|---|---|---|---|
| group | |||||||
| 17 | 10 | 9 | 8 | 6 | 6 | 3 | 1 |
| 18 | 9 | 8 | 7 | 7 | 6 | 4 | 2 |
| 19 | 10 | 10 | 9 | 5 | 3 | 2 | 1 |
| 20 | 15 | 15 | 14 | 11 | 6 | 2 | 1 |
| 21 | 9 | 9 | 9 | 8 | 6 | 3 | 1 |
| 22 | 8 | 8 | 8 | 3 | 2 | 2 | 2 |
| 23 | 6 | 4 | 4 | 3 | 3 | 2 | 1 |
実際に必要だった時には上のようなコードにしたのだが、この記事を書く為に度数のヒートマップを次のようにして描画したら、単にこのmapdfを右から累積すれば良いことに気付いた。データ数が多い時の処理時間も断然短い。
# draw heatmap
mapdf = df.pivot_table(index='group', columns='val', aggfunc='size', dropna=False)
sns.heatmap(mapdf, cmap='Oranges', annot=True, cbar=False)
●コード例3
# Successful trial 3
mapdf = df.pivot_table(index='group', columns='value', aggfunc='size', dropna=False)
result = mapdf.fillna(0).transform(lambda d: d[::-1].cumsum()[::-1], axis=1).astype(int)
result
| val | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|
| group | |||||||
| 17 | 10 | 9 | 8 | 6 | 6 | 3 | 1 |
| 18 | 9 | 8 | 7 | 7 | 6 | 4 | 2 |
| 19 | 10 | 10 | 9 | 5 | 3 | 2 | 1 |
| 20 | 15 | 15 | 14 | 11 | 6 | 2 | 1 |
| 21 | 9 | 9 | 9 | 8 | 6 | 3 | 1 |
| 22 | 8 | 8 | 8 | 3 | 2 | 2 | 2 |
| 23 | 6 | 4 | 4 | 3 | 3 | 2 | 1 |