以前に回帰直線を求めることと主成分分析は似ていると書いたが、ちょっと無理があり過ぎたかも知れない。なぜか主成分分析が因子分析より知名度が低いのが気に入らなくて、メジャーなものと結びつけたくて書いたのだが、やっぱり回帰分析と主成分分析は全然違う。回帰分析は目的変数を説明変数で説明しようとするものであり、主成分分析はデータの傾向を見るものである。通常、回帰直線を求める際に最小にする誤差は目的変数軸上の誤差であるが、第一主成分を求める為に最小にする誤差は全変数が構成する空間での誤差である。
筆者は、主成分分析は多変量解析の基本かつ最も重要であると考えており、学生時代には趣味のプログラミングのネタにするほど惚れ込んだが、因子分析はあまり好みでないのである。暴走ついでにさらに暴走すると、筆者の中では、
| A群 | B群 | C群 |
|---|---|---|
| 因子分析 | 主成分分析 | 回帰分析 |
| Linux | FreeBSD | OpenBSD |
| Ruby | Python | Perl |
| Windows | Mac | UNIX |
| Sleipnir | Lunascape | Firefox |
| 秀丸 | サクラエディタ | Emacs |
閑話休題。今回は重回帰分析を復習する。一次回帰直線が、xを説明変数、yを目的変数とし、直線y^=a x+bの係数aと切片bをデータから求めたものだとすると、重回帰分析はそのxを複数次元にしたもの、
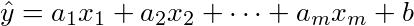
の係数aiとy切片bを求めるものである。
便宜上、上のbをa0と書き、
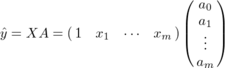
と行列の積で表すことにする。
n個のデータの組(yi, x1i, x2i, x3i, ...)(1<=i<=m)が得られた時、誤差をeiとすると、

である。以下、これをY=XA+Eと書く。
yの誤差eiの2乗和が最小になるようにAを求めるとすると、

であり、これはaiの2次関数なので、これを偏微分して0になるAが答であるから、

なので

という計算で求められることがわかる。(XTX)が正則でないと逆行列が存在しないという問題はあるが、異なるデータの個数が説明変数の数より少ないとか、中身が0だらけのぜろりとしたデータでない限りは正則だろうから、とりあえず気にしないことにする。
試しに次のサンプルデータのバグ数について計算してみる。
| 部品 | バグ数 | 開発規模 | 関係者数 | 疲労度 |
|---|---|---|---|---|
| A | 7 | 0.9 | 3 | 5 |
| B | 15 | 2.1 | 1 | 8 |
| C | 10 | 1.2 | 4 | 9 |
| D | 7 | 1.2 | 1 | 7 |
| E | 6 | 0.3 | 5 | 9 |
| F | 5 | 0.6 | 9 | 3 |
| G | 7 | 0.9 | 2 | 2 |
| H | 5 | 0.3 | 6 | 3 |
| I | 6 | 0.3 | 5 | 8 |
| J | 7 | 0.6 | 3 | 4 |
dat:read_matrix("bugs.dat");
n:10$ /*標本数*/
p:3$ /*説明変数の数*/
Y:submatrix(dat,2,3,4); /*1列目を取り出す(2-4列目を除去)*/
X1:submatrix(dat,1); /*2列目以降を取り出す(1列目を除去)*/
X:map(lambda([x],append([1],x)),X1); /*X1の左端に要素が全て1の列を追加*/
A:invert(transpose(X).X).transpose(X).Y; /*回帰係数*/
fpprintprec:4$
float(A);| a0 | 2.1 |
|---|---|
| a1 | 4.612 |
| a2 | 0.02896 |
| a3 | 0.2436 |
この結果がどれくらい元データに合ってるかを、Yの値で見てみる。
/*元データ、回帰式による推定値、誤差*/ [Y, X.A, Y-X.A];
| 元データY | Yの推定値Y^ | Y-Y^ |
|---|---|---|
| 7 | 7.556 | -.5558 |
| 15 | 13.76 | 1.237 |
| 10 | 9.943 | .05743 |
| 7 | 9.369 | -2.369 |
| 6 | 5.821 | 0.179 |
| 5 | 5.859 | -.8589 |
| 7 | 6.796 | 0.204 |
| 5 | 4.388 | .6115 |
| 6 | 5.577 | .4226 |
| 7 | 5.929 | 1.071 |
YとY^が十分近いので、これでも満足なのだが、統計学にはこの回帰分析結果をきちんと検定する方法が存在するようである。
その前に一応、よくある指標を計算する。以下、データ数をn、説明変数の数をpとする。
load(descriptive) load(distrib) n:10$ p:3$ /*重相関*/ R:cor(addcol(Y,X.A)),numer; /*決定係数(寄与率)*/ R^2; /*自由度補正済み決定係数*/ 1-(1-R[1,2]^2)*(n-1)/(n-p-1);
| 重相関 | 0.9361 |
|---|---|
| 決定係数 | 0.8762 |
| 自由度修正決定係数 | 0.8143 |
これは置いといて、まず、回帰式全体の有効性を検定する。これには、回帰分散÷残差分散、

という値が自由度p,n-p-1のF分布に従う、というのが使えるらしい。YとY^の誤差の分散が十分に小さいかどうかを調べようとするものと言えるだろう。
結果E: Y-X.A$ /*回帰分散*/ Y_hat: X.A-mean(Y)[1]$ Vy: transpose(Y_hat).Y_hat/p,numer; /*残差分散*/ Ve: transpose(E).E/(n-p-1); /*回帰方程式のF値*/ f:Vy/Ve; /*そのF値以上の発生確率*/ 1-cdf_f(f,p,n-p-1);
| F値 | 14.16 |
|---|---|
| P(F(3,6)>14.16) | 0.03951 |
次に、回帰係数aiそれぞれの有効性を検定する。これには、回帰係数÷標準誤差=
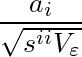
(sijは共変動行列(=n×共分散行列)の逆行列の要素)
という値が自由度n-p-1のt分布に従う、というのを使う。定数項a0については、siiの部分は次のような式になるが、同じようにt値が求められる。

/*共変動行列の逆行列*/ Sinv: invert(cov(X1)*n); /*標準誤差(係数項)*/ Se[i]:=sqrt(Sinv[i,i]*Ve); /*標準誤差(定数項)*/ Se[0]:sqrt((1/n + sum(sum(mean(X1)[i]*mean(X1)[j]*Sinv[i,j],j,1,p),i,1,p))*Ve); for i:0 thru 3 do print(Se[i])$
| i | aiの標準誤差 |
|---|---|
| 0 | 1.863 |
| 1 | 1.023 |
| 2 | 0.2303 |
| 3 | 0.1661 |
/*回帰係数のt値、|t|値がそれより大きい確率*/ t[i]:=A[i+1,1]/Se[i]$ for i:0 thru 3 do print(t[i], 2*(1-cdf_student_t(t[i],n-p-1)))$
| i | t値 | 確率 |
|---|---|---|
| 0 | 1.128 | 0.3025 |
| 1 | 4.507 | 0.004074 |
| 2 | 0.1257 | 0.904 |
| 3 | 1.467 | 0.1928 |
もちろん、以上のような計算は、R(フリーの統計処理ソフト)やExcelを使うと一発である。
Rで計算すると、次のようになる。(先頭が">"の行が入力部分)
> data1 <- read.table("bugs.dat")
> X <- data.frame(data1[2:4])
> Y <- data1[,1,drop=TRUE]
> summary(lm(Y~.,X))
Call:
lm(formula = Y ~ ., data = X)
Residuals:
Min 1Q Median 3Q Max
-2.3685 -0.4025 0.1915 0.5643 1.2374
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.10044 1.86263 1.128 0.30252
V2 4.61167 1.02326 4.507 0.00407 **
V3 0.02896 0.23034 0.126 0.90404
V4 0.24358 0.16607 1.467 0.19281
---
Residual standard error: 1.289 on 6 degrees of freedom
Multiple R-squared: 0.8762, Adjusted R-squared: 0.8143
F-statistic: 14.16 on 3 and 6 DF, p-value: 0.003951
もちろん、今回のMaximaによる計算は、先にRによる結果があって、同じものが得られるようにがんばったものである。こんなに大変だとは思わなかった。
どうでもいいが、筆者はA群に書いたLinuxやWindowsを使わない訳ではない。どちらかというと硬派で右翼なB群の方が好きというだけのことで、筆者もA群の方にはるかに恩恵を受けている。A群とB群の棲み分けは必要だと思うし、筆者のような人間のために、ぜひそういう特徴は損なわれないで頂きたいものである。
因子分析は、主成分分析と同じ計算方法を用いることもあるなど、手段を選ばない所があると思うので、筆者としてはA群なのである。
(2010/10/24追記)s00の導出方法
標本の説明変数側が
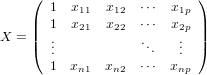
の時(xijのiとjを上記のものと逆に書いているが同じ意味)、定数項以外の平均が0になるように平行移動して
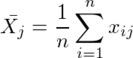
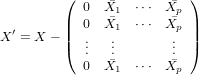
とすると、X'と共変動行列Sijとの間に
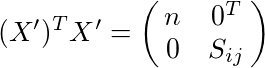 ...(1)
...(1)
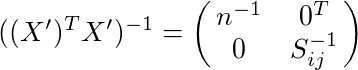 ...(1')
...(1')
というのが成り立つようになる。これを使って、Var(A)を計算する。
上記と同様に、YとX'A'との誤差の2乗和が最小になるような回帰係数A'について、「正規方程式」
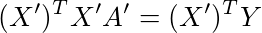 ...(2)
...(2)
が成り立つ。このA'は定数項以外の成分はAと同じなので、
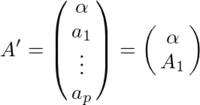
と書くことにすると、(2)は(1)を使って
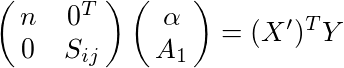
と書き換えることができ、
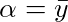 と
と
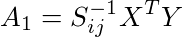
がわかる。
これ以降、推定量を表す変数には^を付ける。これまでのAはA^であり、以降のAは母集団の回帰係数である。
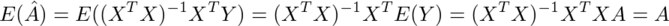
であることからA^がAの不偏推定量であることがわかり、
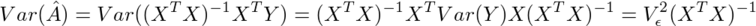
である。これと(1')から、
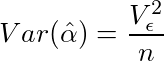
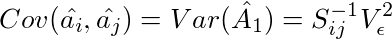
がわかる。
問題のVar(a0)については、
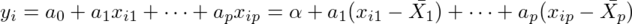
の関係より
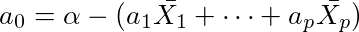
であるから、
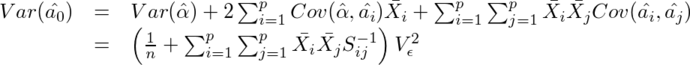
となる。
理系学生
どうして定数項の標準誤差はサンプル数の逆数に、各説明変数の積を共分散でに近い形で除することで求まるのですか?
どうしても導出方法が知りたいです。
ぜひ教えてください。
ynomura
コメント欄に画像が貼れないので、上に追記しました。