前回のエントリーの秘書問題をきちんと解く。
問:以下の条件で、結果としてなるべく順位の高い人が選べるようにするには、どのようにすれば良いか。
・n人の応募者から必ず1人を選ぶ。
・1人ずつ面接し、その場で採用するかどうかを伝える。採用したら、残りの人は面接しない。採用しなければ、その人は2度と選べない。
・応募者は、それまでに面接した人の中で、必ず順位付けされる。応募者の良し悪しは、その暫定順位でしか判断できない。
解:
まず、j番目の応募者の暫定順位(それまでのj人中の順位)がxの時、その応募者が全n人中の何位であるかの期待値を求める。全n人中の順位をyとすると、この期待値は、(順位×確率)の和なので、E(y)=ΣyP(y)のようになる。j人中x位の人がn人中y位である確率は、
1 ...... y ...... n
↓
1 ... x ... j
という対応を考えると、j人の組み合わせnCj通りの中で、yの左側(y-1)人の内(x-1)人がxの左側に入って、yの右側(n-y)人の内の(j-x)人がxの右側に入る確率なので、P(y)=(y-1)C(x-1) × (n-y)C(j-x) ÷ nCjである。これを使うと、yの期待値は
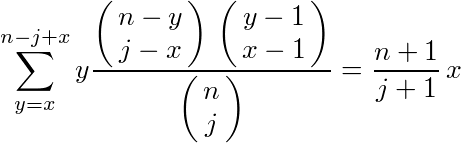
となるらしい。(参考文献(1)による。この変形は私にはできなかったが、このP(y)は「超幾何分布」の形をしてるので、その知識を使えば簡単な計算で求まるのだと思う。)このE(y)を、以後y(j,x,n)と書く。
次に、最後の応募者の場合から、具体的な手順を考える。j-1番目までの応募者を採用しない時の最終的な採用者の期待順位をR(j,n)とする。
n-1番目までの応募者を採用せず、n番目の応募者を面接する場合、R(n,n)=n番目の応募者の期待順位=1位〜n位の平均=(n+1)/2である。
n-1番目の応募者については、その人が暫定x位の時、その人の最終的な期待順位はy(n-1, x, n)であり、その人を選ばない時の期待順位はR(n,n)である。従って、y(n-1, x, n) ≦ R(n,n)ならその人を採用すれば良いということになる。n-1番目の人がある暫定x位である確率は1/(n-1)なので、min{a,b}をa,bの小さい方とすると、R(n-1,n) = 1/(n-1) * Σ min{ y(n-1, x, n), R(n,n) }と書ける。
これは、n-1番目の応募者に限らず、1≦j<nの全てのjについて同じである。すなわち、j番目の応募者が暫定x位の時、その人の最終的な期待順位はy(j, x, n)であり、その人を選ばない時の期待順位はR(j+1,n)である。従って、y(j, x, n) ≦ R(j+1,n)ならその人を採用すれば良いというのが答である。R(j,n) = 1/j Σ min{ y(j, x, n), R(n,n) }、yを展開すると
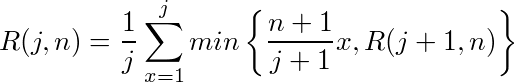
なので、R(j,n)は末端のR(n,n)から逆向きに帰納的に(backward inductionと言うらしい)計算できる。
n=10の場合、採用する人の期待順位を最小にするために、j番目の人が暫定何位以内ならその人を選べば良いかは、次のようになる。3列目は、その人まで達した時の最終的な期待順位である。
| j | threshold | R(j,10) |
|---|---|---|
| 9 | 5 | 4.28 |
| 8 | 3 | 3.59 |
| 7 | 2 | 3.15 |
| 6 | 2 | 2.89 |
| 5 | 1 | 2.68 |
| 4 | 1 | 2.56 |
| 3 | 0 | 2.56 |
n=20の場合は次のようになる。
| j | threshold | R(j,20) |
|---|---|---|
| 19 | 10 | 8.01 |
| 18 | 7 | 6.62 |
| 17 | 5 | 5.70 |
| 16 | 4 | 5.05 |
| 15 | 3 | 4.56 |
| 14 | 3 | 4.18 |
| 13 | 2 | 3.89 |
| 12 | 2 | 3.64 |
| 11 | 2 | 3.46 |
| 10 | 1 | 3.30 |
| 9 | 1 | 3.17 |
| 8 | 1 | 3.06 |
| 7 | 1 | 3.0021 |
| 6 | 1 | 3.0017 |
| 5 | 0 | 3.0017 |
参考文献
(1)「タイミングの数理 最適停止問題」穴太克則 著(朝倉書店)
以上の計算に用いたMaximaの入出力を示す。
y(j,x,n) := (n+1)/(j+1)*x$(Sは期待順位がR(j+1,n)より低くなる暫定順位)
R(j,n) := if j=n then (n+1)/2 else (1/j) * sum(min((n+1)/(j+1)*x, R(j+1,n)), x, 1, j)$
S(j,n) := if j=n then n else floor((j+1)/(n+1)*R(j+1,n))$
makelist([j,S(j,n),R(j,n)], j, 1, 10), n=10;
最初は再帰的な式としてこんな感じに書いたのだが、これだとjが小さいとR(j,n)を何回も何回も計算してしまうため、非常に時間がかかる。そのため、一度計算したR(j,n)をリストに残していくようにする。
y(j,x,n) := (n+1)/(j+1)*x$
R(j,n) := if j=n then R[j] else (1/j) * sum(min((n+1)/(j+1)*x, R[j+1]), x, 1, j)$
S(j,n) := if j=n then n else floor((j+1)/(n+1)*R(j+1,n))$
n:10$
R: makelist(0,j,1,n)$
R[n]: (n+1)/2$
for j:1 thru n-1 do R[n-j]: R(n-j,n)$
makelist([j,S(j,n),R(j,n)], j, 1, 10), numer;
(%o359) [[1,0,2.557936507936508],[2,0,2.557936507936508],[3,0,2.557936507936508],[4,1,2.557936507936508],[5,1,2.677248677248677],[6,2,2.888227513227513],[7,2,3.153769841269841],[8,3,3.590277777777778],[9,5,4.277777777777778],[10,10,5.5]]
n: 20$
R: makelist(0,j,1,n)$
R[n]: (n+1)/2;
for j:1 thru n-1 do R[n-j]: R(n-j,n)$
makelist([j,S(j,n),R(j,n)], j, 1, 20), numer;
(%o362) 21/2
(%o364) [[1,0,3.001731675831908],[2,0,3.001731675831908],[3,0,3.001731675831908],[4,0,3.001731675831908],[5,0,3.001731675831909],[6,1,3.001731675831908],[7,1,3.002078010998289],[8,1,3.064924346164671],[9,1,3.169437347997719],[10,1,3.303117016497435],[11,2,3.458008806209271],[12,2,3.643121874255775],[13,2,3.887130864491547],[14,3,4.184791021671827],[15,3,4.562461300309598],[16,4,5.046826625386998],[17,5,5.69969040247678],[18,7,6.616228070175441],[19,10,8.013157894736842],[20,20,10.5]]
ついでに、「37%の法則」による期待順位と、前回の戦略による期待順位も計算して、比較してみる。上記の正しい戦略だと、n=10で約2.56位、n=20で約3.00位、n=100で約3.60位である。
c人目以降の暫定1位の人を採用する(n人目は必ず採用する)場合の最終的な期待順位は、Σ(j人目が暫定1位の確率)*(暫定2位が最初の(c-1)人に含まれる確率)*(j人中暫定1位の最終順位の期待値)+(最後まで暫定1位が現れない確率)×(最後の人の期待順位)=
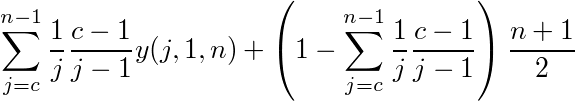
となる。37%の法則はこれのc=n*0.37(小数点以下切り上げ)としたものだから、次のように計算できる。
/* 37% rule */
rank1(c,n) := sum((1/j)*(c-1)/(j-1) * y(j,1,n), j, c, n-1) + (1-sum((1/j)*(c-1)/(j-1), j, c, n-1)) * (n+1)/2;
rank1(4,10),numer;
rank1(8,20),numer;
rank1(37,100),numer;
(%o372) 3.025
(%o373) 4.987499999999999
(%o374) 19.54486486486487
n=10で約3.0位、n=20で約4.99位、n=100で約19.5位である。1位を狙いすぎると、平均的には結果が悪くなるということになる。
前回の方法の場合は、j番目の応募者を採用するのは、暫定順位が
F(j,n) := floor(0.5+j/(n-j+1));より小さい場合で、j番目の応募者まで面接する確率が
P(j,n) := (1-sum(P(k,n)*F(k,n),k,1,j-1))/j;なので、期待順位は
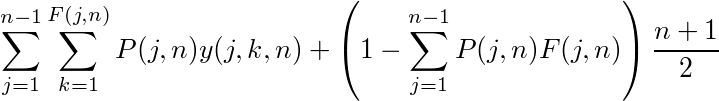
のようになる。
rank2(n) := sum(sum(P(j,n) * y(j,k,n), k, 1, F(j,n)), j, 1, n-1) + (1-sum(P(j,n) * F(j,n), j, 1, n-1)) * (n+1)/2;n=100については、時間がかかるので、リストを使う。
rank2(10),numer;
rank2(20),numer;
(%o8) 2.559027777777779
(%o9) 3.078048344844011
n: 100;最終的な期待順位は、n=10で約2.56、n=20で約3.08、n=100で約4.30であった。面倒な再帰計算が不要な前回の方法、すなわち、まだ会ってない応募者がx人の時に今面接している人の順位が0.5+(n-x)/(x+1)より小さければ採用するという方法でも、nが20くらいまでだと悪くない近似のようだ。
F : makelist(floor(0.5+j/(n-j+1)),j, 1, n);
P : makelist(1, k, 1, n);
for j:1 thru n do P[j]: (1-sum(P[k]*F[k],k,1,j-1))/j$
rank2 : sum(sum(P[j] * y(j,k,n), k, 1, F[j]), j, 1, n-1) + (1-sum(P[j] * F[j], j, 1, n-1)) * (n+1)/2, numer;
(%o65) 4.303130024510656
コメント