「秘書問題」(secretary problem)というのは、非常に奥深い問題で、数理科学の「最適停止理論」における1つの重要な分野となっており、未解決の問題も少なくないらしい。
前のエントリーに書いた、37%の法則が成り立つ問題は、秘書問題の最も単純なものである。秘書問題に倣って秘書を面接で選ぶという表現に変えると、前のエントリーの問題は、応募者の中の最高の人以外は外れという条件の問題であるが、現実の問題としては、できるだけ最高の人を選ぶことだけを考えればいいとは限らない。誰か1人を選ばないといけない場合、最後の応募者まで採用を見送ると、最後の人はどんな人でも選ばないといけない。その1つ前の、残り1人(まだ面接していない応募者が1人)の時点で、前回の37%の法則の戦略に従うと、今面接している人がこれまでの中の2位であっても、残りの1人が1位である可能性に期待して見送るのであるが、なるべくいい人を選びたい場合は、残り1人で暫定2位であれば、残りの1人が2位以内に入る確率は(応募者が十分多いとすると)極めて低いので、暫定2位の人を採用するのが当然である。
このことからも直感的にわかる通り、1位の人を選ぶ確率を最大化するのとなるべく上位の人を選ぶのとは一般に両立しない。なるべく上位の人を選ぶ、というのを、順位の期待値を最小化する、と定義すると、1位の人を選ぶ確率を最大化するのと順位の期待値を最小化するのを同時に満たす最適停止戦略は存在しないことが数学的に示されているらしい。
という訳で、今回は次のような問題を考える。
・n人の応募者から1人を選ぶ。
・1人ずつ面接し、その場で採用するかどうかを伝える。採用したら、残りの人は面接しない。採用しなければ、その人は2度と選べない。
・応募者の良し悪しは、既に面接した応募者と比べてどうかでしか判断できない。絶対評価で何点というのは無く、あの人と比べてどうか、しかわからない。また、優劣は必ず付けられ、必ず順位付けが可能である。
・結果としてなるべく順位の高い人が選べるようにする。
必ず誰か1人は選ばないといけないということと、最後の1点以外は、前のエントリーの問題と同じである。
この問題は既に解かれていて、nを大きくすると順位の期待値の最小が約3.87に収束する(期待順位がそれより小さい戦略は存在しない)という摩訶不思議な定理になっているのだが、あまりにも難しいので、今回は単純な方法で考えてみる。
xを残りの応募者の数(まだ面接していない人数)とする。
x=0(今面接している人が最後の応募者)の時、その人を選ぶしか無い。
x=1の時、今面接している人を含むn-1人を1位〜n-1位に並べ、残りの人がその間または1位の上、n-1位の下のどこかに入ると考えると、入る場所はnヶ所なので、これを0.5位、1.5位、…、(n-0.5)位とすると、残りの人の順位の期待値はn/2なので、今面接している人の順位がn/2より小さければ選ぶ。(n/2以下なら、としても良い)
x=2の時、同様にこれまでの1位〜n-2位に対して残りの2人が0.5位、1.5位、…、(n-2+0.5)位の(n-1)ヶ所のどこかに入ると考えると、残りの2人のいい方の順位の期待値は、1人目の順位をkとすると
(2人目がkよりいい確率)*(2人目の順位の期待値)+(1 - 2人目がkよりいい確率)*k
であり、1人目の順位がkである確率は1/(n-1)なので、
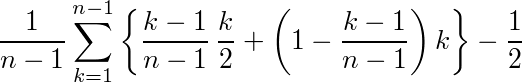
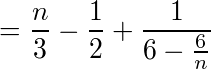
と計算できるので、今面接している人の順位がそれより小さければ選ぶ。
x>2の時、残りのx人の最高順位の期待値を同様に求めるのは難しいので、代わりに一様分布に従うx個の標本の最小値を求めてみる。
標本が0-1の一様分布に従う時、n個の標本の最大値がyより小さい確率は、全ての標本がyより小さい確率だから、ynである。これは最大値がyになる確率の累積密度だから、確率密度関数はそれを微分してn yn-1である。従って、最大値の期待値は、
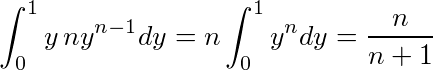
である。標本を全て(1-標本)にすると、最小値の期待値は1 - n/(n+1) = 1/(n+1)ということになる。
これを使うと、x>2の時、残りのx人の最高順位の期待値は、0.5+(0〜(n-x)の値を取るx個の標本の最小値の期待値)=0.5+(n-x)/(x+1)と概算できるので、今面接している人の順位がこれより小さければその人を選べば良い、と考えられる。
上の計算に沿って、n=10で残りがx人の時、今面接している人が何位以内ならその人を選べば良いかを表にしてみる。
| x | rank |
|---|---|
| 1 | 5 |
| 2 | 3.17 |
| 3 | 2.25 |
| 4 | 1.7 |
| 5 | 1.33 |
| 6 | 1.07 |
| 7 | 0.88 |
x=1の時(9人目)は暫定5位以内なら採用、x=2の時(8人目)は暫定3位以内なら採用、x=3の時は暫定2位以内なら採用すれば良く、x=7の時(3人目)は暫定1位でもパスすべしということになる。
n=20についてもやってみる。
| x | rank |
|---|---|
| 1 | 10 |
| 2 | 6.5 |
| 3 | 4.75 |
| 4 | 3.7 |
| 5 | 3 |
| 6 | 2.5 |
| 7 | 2.13 |
| 8 | 1.83 |
| 9 | 1.6 |
| 10 | 1.41 |
| 11 | 1.25 |
| 12 | 1.12 |
| 13 | 1 |
| 14 | 0.9 |
x=1の時は10位以内なら採用、x=2の時は6位以内なら採用、(中略)x>13の時は1位でもパスすべしということになる。
以上の計算は、残りの応募者の最高順位の期待値を基準に考えており、同じ戦略を続けて選ぶ人の順位の期待値とは異なるので、正確ではない。(xが大きい時にハードルが高めになっている)
ちなみに、標本が0-1の一様分布に従う時、n個の標本の最小値の期待値が1/(n+1)となることは、n個の標本を小さい順から並べた時にk番目の標本の値(順序統計量)がベータ分布Β(k, n+1-k)に従うことからも求められるらしい。Β(α,β)の期待値はα/(α+β)なので、Β(1,n+1-1)=Β(1,n)の期待値は1/(n+1)となる。
一応、今回使ったmaximaの入出力をメモする。
(%i1) 1/(n-1)*sum((k-1)/(n-1)*k/2 + (1-(k-1)/(n-1))*k, k, 1, n-1), simpsum, ratsimp;
(%o1) (2*n^2-n)/(6*n-6)(%i2) rank(n,x):=0.5+(n-x)/(x+1);
(%i4) for x:1 thru 14 do print(rank(20,x));
(%i3) for x:1 thru 7 do print(rank(10,x));
5.0
3.166666666666667
2.25
1.7
1.333333333333333
1.071428571428571
0.875
(%o3) done
10.0
6.5
4.75
3.7
3.0
2.5
2.125
1.833333333333333
1.6
1.409090909090909
1.25
1.115384615384615
1.0
0.9
(%o4) done
コメント