我ながら物好きであるという仮説が棄却されなさそうであるが、大学の時に買う羽目になった統計学の教科書を引っ張り出して、推定量というものを勉強している。そこには、推定量の好ましい性質として不偏性と一致性が挙げられ、次に推定量同士を比べる話が出てきて、その後に有効推定量、最尤推定量が出てくる。この教科書のこの流れのために、有効推定量や最尤推定量は不偏性と一致性を満たすんだろうとずっと誤解していた。何せ「有効」「最*」なのだから。
特に「最尤推定量」の名前の意味は「最ももっともらしい推定量」であり、まるでキャッチフレーズのように「最尤推定」に付け加えられ、そのインパクトによって、これぞ最強の推定量というイメージが刷り込まれてしまう。大学の研究室にも、最尤推定量の意味を理解せず、「推定」という言葉が出てくる度に、馬鹿の一つ覚えのように「最尤推定を使えばいいじゃない」と言っていた教官がいた。実データが取りようが無い(統計量が無い)ものの話をしていても「最尤推定」という単語を持ち出されて、私を含め、学生たちは皆、そのセリフに降参するしか無かった。
余談はさておき、よく読むと、どうやら有効性(efficiency)と不偏性(unbiasedness)、一致性(consistency)とは直接は関係ないようである。例えば標本分散は一致推定量であるが不偏ではない(不偏分散は不偏かつ一致推定量)し、逆に不偏だが一致性が無い場合もある。有効推定量や最尤推定量にも不偏でない(biasedな)ものがあるし、最尤推定量にも一致性が無いものがあったりするらしい。
一致性というのは、数式で書くと、実際のパラメーターをθ、推定量をθ^、Pを確率、nを標本数として
 (または不等号を逆にして=1)
(または不等号を逆にして=1)
とちょっとアレであるが、要するに標本の数が多ければ推定量が実際の値に近づく性質のことである。意図的に外すかよっぽどチョンボしない限りはそれを満たすのが当たり前な気がするが、推定量が多項式でない場合は気にした方が良いのかも知れない。
不偏推定量であるが一致推定量でない極端な例としては、標本をX1...Xnとして、平均θの推定量θ^=X1やθ^=Xnがある。標本がいくら増えてもその中の1つしか使わなければ精度が上がらないので、当たり前である。標本を全て使っても一致推定量でない例として、こういうのを考えてみた。
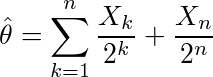
これは、実際の分散をσ2とすると
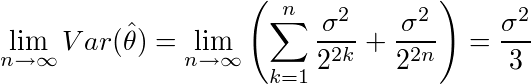
であり、nを大きくしても分散が0にならないので、θ^はθに収束しない(はず)。(ちなみに、普通にθ^を標本平均(X1+X2+...+Xn)/nとすると、Var(θ^)=σ2/nなので、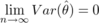 となり、θ^はθに限りなく近づく)
となり、θ^はθに限りなく近づく)
有効推定量というのは、クラメル=ラオの不等式
![Var(¥hat{¥theta}) ¥geq ¥frac{1}{n E¥left¥{¥left[¥frac{¥partial}{¥partial¥theta}¥log P(X)¥right]^2¥right¥}} ¥equiv ¥sigma_0^2](/archives/images/cramer-rao1.png)
の等号が成立する(Var(θ^)が「クラメル=ラオの下限」σ02になる)ようなθ^、つまり不偏推定量の中で分散が最小になるもののことである。確率の対数をθで偏微分して2乗して平均して逆数にして訳がわからないが、対数が出てくるのは、AとBとCが同時に起こる確率がP(A)×P(B)×P(C)なのでその対数がlogP(A)+logP(B)+logP(C)となるように、標本それぞれが同時に起こる確率が線形和になるためのもので、偏微分は飛ばして、2乗の平均は誤差の2乗和の意味で出てくるのだと思う。
上記の不等式を解く代わりに、

の右辺がθを含まなくできるK(但しKはXiは含まない)があれば、その時のθ^が有効推定量、という定理が使える。それを使って、X1...Xnが平均μ、分散θの正規分布に従う標本の場合のθの有効推定量を求めてみる。確率密度関数は
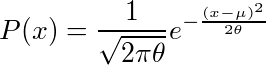
なので、
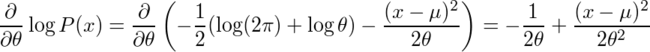
であり、

なので、K=2θ2/nとするとθが消えることがわかる。従って、

であり、標本分散がθの有効推定量である。
標本分散は不偏ではないので、正規分布の分散の有効推定量は不偏推定量ではないことがわかる。
一致推定量でない最尤推定量の例は、下のリンク先にある。
Inconsistent Maximum Likelihood Estimation: An “Ordinary” Example « Radford Neal’s blog
このページによると、標本が
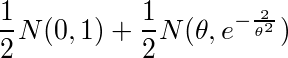
(N(μ,σ^2)は正規分布)に従う場合、その最尤推定量は一致推定量にならないらしい。
また、下のリンク先にも、「ノンパラメトリックな最尤推定量は一致性が無いことが示された」というようなことが書かれている。
Efficient estimation from right-censored data when failure indicators are missing at random(Project euclid)
コメント