以前にt分布を使うパラメーターの区間推定の方法を覚えたが、この前ちょっと推定の実践のネタを思いついてやってみようとしたら、そのパラメーターが正規分布に従うものではないことに気付き、1手目でつまずいた。これでは勉強した意味が無いと思い、推定というものの基礎を勉強し直すことにした。
区間推定をするにもまず、その区間の基準となる値(推定量)を点推定しないと始まらない。その点推定量が満たすのが好ましい性質として、不偏性と一致性がある。推定量θ^がパラメーターθの不偏推定量であるとは、
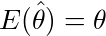 ...(1)
...(1)
が成り立つことをいう。
出た 。学生時代にこのθの上の屋根の意味が理解できなかったことが、私が推定・検定の1手目でつまずいた原因の1つであることは間違いない。そもそもなぜ統計学では推定するパラメーターをθと書くのか。高校の三角関数の授業で習って以来、私にとってはθといえば角度に違いないのであり、パラメーターをθと表すのは、円周率をxと表すとか、y=ax+bのxとyが定数でaとbがグラフの縦軸・横軸であるくらいの混乱の元である。
。学生時代にこのθの上の屋根の意味が理解できなかったことが、私が推定・検定の1手目でつまずいた原因の1つであることは間違いない。そもそもなぜ統計学では推定するパラメーターをθと書くのか。高校の三角関数の授業で習って以来、私にとってはθといえば角度に違いないのであり、パラメーターをθと表すのは、円周率をxと表すとか、y=ax+bのxとyが定数でaとbがグラフの縦軸・横軸であるくらいの混乱の元である。
そもそも、θ^がθの推定値だとしたら、(1)が成り立たないとはどういう状態なのだろうか?それに、θが未知だからθを推定するのに、θ^の平均がθであることをどうやって確認するのか?
...という疑問を持ったのは筆者だけなのだろうか。
これは、θが確率変数のパラメーターであり、その推定量θ^を標本から求める方法を決めた時、仮にθによって決まる母集団からの標本を使った場合、θ^の平均がθに一致するなら、そのθ^は不偏推定量である、という意味らしい。
例題として、X1〜Xnが平均μ、分散σ2の母集団からの標本として、まず標本平均X~=E(X)=1/n ΣXiがμの不偏推定量かどうかを考える。
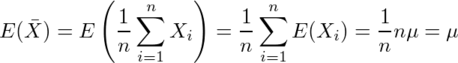
従ってX~はμの不偏推定量である。
次に、標本分散 、不偏分散
、不偏分散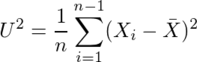 がσ2の不偏推定量かどうかを考える。
がσ2の不偏推定量かどうかを考える。
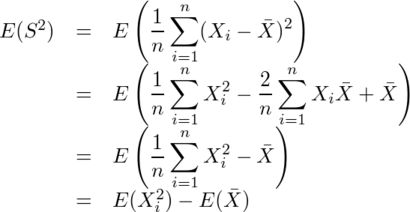
ここで、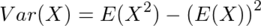 の公式と
の公式と の公式を用いると、
の公式を用いると、
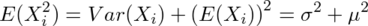

が求まるので、

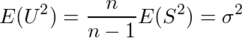
となる。従って、S2はσ2の不偏推定量ではなく、U2はσ2の不偏推定量である。
細かすぎる感じもするが、筆者はここまでやらないと理解できなかった。
以前、不偏分散の理解に苦しんだことがあったが、今日やっと理解できた気がする。
コメント