高校時代は確率が得意中の得意だった私が、大学の統計学の講義にはすぐついていけなくなった。高3の時は、授業で順列と組み合わせの公式を覚えた途端、ほとんど全ての問題が難なく解けた。周りには理解につまずく人がいたが、私にはなぜ理解できないのかがわからなかった。大学2年の時に受けた統計学の講義も、半年くらいは割と楽についていってたが、ある時点から突然理解できなくなった。それは、平坦な道に突如現れた高い壁だった。どちらかというと興味があった科目なので、教科書をじっくりと何度も読んで理解しようとしたが、特に数式や日本語が難しい訳でもないのに、全然頭に入らなかった。なぜ理解できないのかがわからない不思議な感覚だった。
「推定・検定」という名前の関門だった。
結局、大学で統計学の講義を3回くらい取って、毎回1から学んだが、いつも確率分布までは理解できるのに、「推定・検定」で手も足も出ず挫折した。3回目の統計学で悟ったのは、t分布とカイ2乗分布が障害ということだった。
それから幾年月、それ以来統計学に接する機会が無かったが、推定・検定のことがずっと気にかかっていた。大学時代に最も興味があった科目の1つでありながら全く私を寄せ付けず、私に最も挫折感を味わわせた推定・検定を克服しない限り、死んでも死に切れない。今更そんなものを勉強して何の役に立つのかと言われようが関係ないのである。
という訳で先々月ぐらいからリベンジを試みているが、やはり相性が悪い。何となく少し理解した気になっても、2週間もするとすっかり忘れてしまい、先に進まない。後半が推定・検定でそれで終わりの入門書チックな統計解析の本を買って読んでるが、後半のみもう4周目くらいである。私以外のこれを読む人には前半と後半、確率分布と推定・検定の間に落差は無いのだろうか。
無駄話はこの辺にして、勉強したことをメモする。
t分布とは、xを平均μ、分散σ2の正規分布N(μ,σ2)に従う標本、(xの上にバー)を標本平均、nを標本の数、sを標準偏差(不偏分散の平方根)とした時、
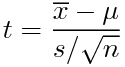
というtが従う分布であり、
χ2分布とは、
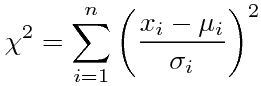
というχ2が従う分布である、というようなことがどこにでも書いてある。
入門書で無ければ、さらにこれらの分布の確率密度関数が、ガンマ関数を使った容赦ない鮮烈な式で書かれる。
これが推定・検定の本題の前に出てくるから厄介だ。
どちらもにわかにはイメージが掴みにくい数式であり、なぜこういうものが必要かを説明される前に、まずこれを覚えて、と言われるのは結構辛いと思う。
それらの分布の意味を理解する前に、使い道を1つくらい知った方が、最初の理解の足掛かりになるし、トータルとして速く理解できるのではないだろうか。
という訳で、t分布の使用例として、母平均の区間推定を考えてみる。
大勢の人が受けたテストの点が正規分布に従うとする。その中の10人の点数(標本)が
70, 60, 40, 80, 40, 60, 30, 80, 50, 90
だとすると、全体の平均点は95%の確率でどの範囲に入ると推測できるだろうか。
ここで、その範囲が(標本平均±t*√(標本分散÷標本数))で求められるというのが、区間推定のありがたい教えである。
上の標本の場合、平均が60、分散が400、自由度(n-1)=9で信頼区間が95%となるtが2.262なので、推定区間は60±2.262√(400/10) ≒ 60±14.3ということになる。標本の平均は60点だが、95%の確率で全体の平均がこの範囲に入るということだ。
標本平均の分散が(標本分散÷標本数)になるというのは定理としてあるので、t分布のtの値というのは、標本の標準偏差を何倍すれば推定区間の幅になるのかを教えてくれるものと考えられる。
χ2分布の使用例として、ばらつきの片側検定を考えてみる。
プログラマーがそれぞれ2,3,3,4,8人の5つのソフトハウスにソフトウェアの開発を委託してるとし、あるプロジェクトにおいてそれぞれのソフトハウスが発生させたバグの数が15,18,14,19,34だったとする。バグの数がプログラマーの数に比例するという仮定は間違ってる方の5%に入る(95%の確率で間違ってる)だろうか。
ここで、((測定値−期待値)の2乗÷期待値)の和、という値がχ2分布に従うので、χ2分布を見ればその発生確率がわかる、というのが、χ2検定のマジカルかつミラクルな教えである。
上の標本の場合、バグが計100件でプログラマーが計20人なので、1人当たり5件、ソフトハウス別では10,15,15,20,40件となるのが期待値である。従って、測定値のχ2の値は、
(15-10)2/10 + (18-15)2/15 + (14-15)2/15 + (19-20)2/20 + (34-40)2/40 ≒ 4.1
である。自由度(5-1)=4で棄却域(有意水準)が5%となる、χ2分布におけるχ2の値は9.49なので、測定値のχ2の値はそれより小さく、95%の確率で起こり得る範囲内であることがわかる。
従って、バグの数がプログラマーの数に比例するという仮定は間違ってるとは言えない。
χ2分布のχ2の値というのは、同時に起こらない複数の事象の発生回数と各々の回数の期待値がわかる場合に、その期待結果とのずれがどれくらいの確率で起こるものかを調べるのに使える、発生回数のばらつきの尺度だと考えられる。
上の計算に用いたMaximaへの入力と出力を記録する。
(%i) load(descriptive); /* 統計関数を使うためのおまじない */
(%i) load(distrib);
(%i) x:[70, 60, 40, 80, 40, 60, 30, 80, 50, 90];
(%i64) mean(x); /* 平均 */
(%o64) 60
(%i65) var1(x); /* 不偏分散 */
(%o65) 400
(%o66) quantile_student_t(0.025,9); /* t分布の累積密度関数が2.5%になるt */
(%o66) -2.262157162055078
(%i67) quantile_student_t(0.975,9); /* t分布の累積密度関数が97.5%になるt */
(%o67) 2.262157162055078
(%i70) 2.262*sqrt(400/10),numer;
(%o70) 14.30614413460175
(%i94) quantile_chi2(0.95,4); /* χ^2分布の累積密度関数が95%になるχ^2 */
(%o94) 9.487729036781154
コメント