t分布を、正規分布に従う標本の平均が従う分布である、という感じに捉えて、なんとなく理解した気になると、1つ疑問が湧いた。正規分布に従う複数の値の和はやはり正規分布に従うのではなかったか?それなら、値の和を変数の数で割ったもの、つまり平均もt分布でなく正規分布に従うはずではないのか?
x1,x2をそれぞれ正規分布N(μ1,σ12),N(μ2,σ22)に従う確率変数とすると、x1+x2はN(μ1+μ2,σ12+σ22)に従う、つまり和の平均は平均の和、和の分散も分散の和となる、というのを正規分布の性質の1つとして教えられている。x1+x2が正規分布に従うなら(x1+x2)/2も正規分布(この場合![]() )に従うはずである。
)に従うはずである。
というか、正規分布N(μ,σ2)に従うn個の標本の平均はN(μ,σ2/n)に従う、つまりn個の平均を取ると分散が1/nになる、という定理を覚えていないと、t分布の式を読むのが難しいと思う。それからしてもやはり標本の平均は正規分布に従うはずである。
そんなことで混乱したのは私だけだろうか?
混乱の原因は、標本平均、標本分散と母平均、毋分散をごっちゃにしたことだった。母平均をμ、毋分散をσ2、標本をx1...xn、標本平均をm= ![]() 、標本分散を
、標本分散を![]() とすると、mはあくまでN(μ,σ2/n)に従うのであって、N(m,Sn2/n)に従うのではないのである。つまり、μやσが不明な場合はmが従う正規分布も不明なのである。
とすると、mはあくまでN(μ,σ2/n)に従うのであって、N(m,Sn2/n)に従うのではないのである。つまり、μやσが不明な場合はmが従う正規分布も不明なのである。
そこで、mやSn2からμの範囲を推定するのにt分布が出てくる。
(※本エントリーではシステムの都合上、標本平均をmと書いたりxバー(xの上にバー)と書いたりするが、両者は同じものである)
...という感じに混乱を解決するのにも私には結構時間がかかったのだが、その間に私の理解を妨げたものの1つが、不偏分散の概念である。
標本分散が
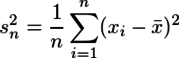
であるのに対して、母平均の区間推定に必要になる不偏分散は
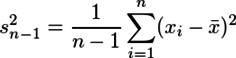
と教わる。nで割るかn-1で割るかの違いだけである。なぜn-1で割るのかというと、「自由度がn-1だから」と教わる。そんなのは丸覚えすれば引っかかる必要の無いことであるが、私の脳はそこで「???」となり先に進まなくなった。
「推定値の不偏分散の自由度が(n-1)である」理由は、ばらつきの指標の元となる
Σ(xi-m)2
のmにm=1/n Σxiという縛りがあるため、mとx1...xn-1が決まるとxnが決まるので、この2乗和がn-1個分しか動かないから、と説明されることが多い。極端な例としては、n=2の時、本当の平均μがわかってれば
Σ(xi-μ)2
はx1の分もx2の分もばらつきに応じて大きくなるのに対して、
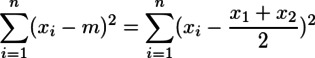
は計算すると
(x1-x2)2/4
となり、標本が2個あるのに、その間の差1個分しかばらつきの値として反映されない。同様の理由により、標本をn個としてもn-1個分しかばらつきの値として加算されないのである。
その説明によって、私は一瞬目から鱗が落ちた気がしたが、まだ納得できなかった。もし標本の数を母集団の大きさと同じにすれば、つまり母集団の全てをサンプルとして拾えば、mが本当の平均になるから、自由度がn-1でも分散は(1/n)Σ(xn-m)2ではないか?
...ここから先はまだ疑問が解けていないが、おそらく推定値の分散と実際のデータの分散は同じ尺度では測れないということのような予感がする。
ところで、2008/11/16時点の日本語のWikipediaの分散の項に、不偏分散の計算、というのが載っている。曰く、
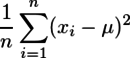
が
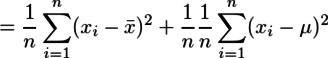
になるので、
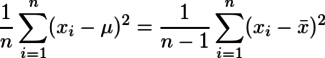
となるとのことである。これだ!と思って計算を追ってみると、途中の
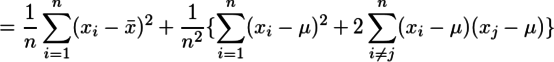
までは確認できたが、その次の
はわからなかった。というか、少なくともn=2として展開してみる限り、そうはならない。=が≒の間違いなのかも知れないが、よくわからない。
結局、私は次のように理解した。上のWikipediaの計算と同じ方針で、![]() として両辺の分散を取ると、分散の加法性から
として両辺の分散を取ると、分散の加法性から
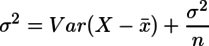
となる。Var(...)の部分は標本分散なので、これを毋分散σ2について解くと、
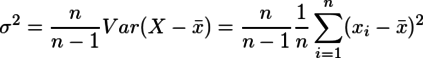
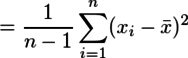
となる。これが標本から推測される毋分散であり、毋分散と同じ尺度で使える不偏分散ということである。
しかし、これは「推定値の不偏分散の自由度が(n-1)である」を前提としてそれ自体を確かめたようなものであり、トートロジーのような気がするので、私がそれで理解したと思ってること自体が混乱してる証拠なのかも知れない。
ついでに、資料によっては、nが小さい時は偏差平方和をnで割ってもn-1で割っても分散としては正確でなく、nが大きい時は大差ないので、nで割った標本分散を使うかn-1で割った不偏分散を使うかはあまり関係ないと書いてある。
何も考えずに、推定値の分散は自由度がn-1なので不偏分散=偏差平方和÷(n-1)、と丸覚えしておく方が幸せなのかも知れない、と思った。
コメント