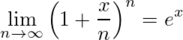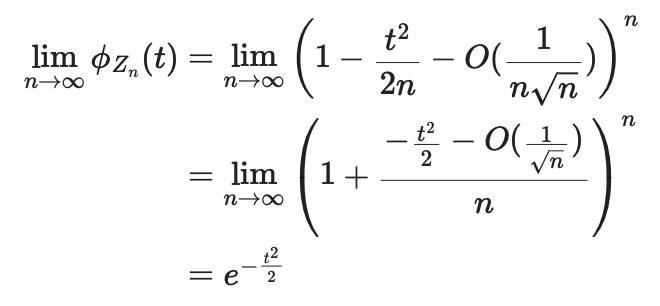前の記事で紹介した、吃音の治癒に関して統計解析した論文
"Spontaneous" late recovery from stuttering: Dimensions of reported techniques and causal attributions
に、筆者にとって馴染みの無い統計学の用語がいくつかあったので、この機会に調べた。
この論文では主成分分析を行っているが、それらの用語は因子分析で用いられるものが多かった。
Kaiser-Meyer-Olkin (KMO) index (§2.3)
主に因子分析の文脈において、データがどれくらい因子分析に適しているかを示す指数。
データ中の各観測変数の妥当性の評価、及び分析モデルの妥当性の評価に用いられる。
MSA(Measure of Sampling Adequacy, 標本妥当性)とも言われる。
定義としては、
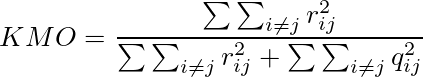
但し、
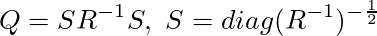
Rはデータの観測変数の相関行列
Qは偏相関行列
rijはRの要素
qijはQの要素
KMOの3つのΣΣ部分において、iについて和を取らなければ、観測変数毎の(i番目の観測変数の)KMO indexとなる。
意味としては概ね、(相関+偏相関)中の相関の割合であり、大きいほど観測変数間に相関がある=共通因子があるということになる。因子分析においては0.8以上が好ましく[3]、0.5未満は"unacceptable"とされているらしい。(0.5だと相関係数と偏相関係数が同じ大きさなので共通因子無しである)
KMO indexが低い場合、変数毎のKMO indexが低い変数を除外する方法や、データ数を増やす方法があるらしい。今回の論文では、KMO indexが0.5を超えるようにデータ数を増やすという使い方がなされた。
主に因子分析の文脈で使われるが、主成分分析でデータを縮約する場合や、共通因子を見つけようとする場合にも使われるようだ。
参考文献
[1] Kaiser-Meyer-Olkin test - Wikipedia
[2] R: Kaiser-Meyer-Olkin criterion
[3] A Modernized Heuristic Approach to Robust Exploratory Factor Analysis
[4] https://htsuda.net/stats/factor-analysis.html
polychoric correlation matrix (§2.3)
ポリコリック相関係数行列。ポリコリック相関係数は、因子分析や主成分分析で順序尺度のデータを適切に扱う為に用いられるもので、順序尺度同士の相関係数を、通常の相関係数(ピアソンの積率相関係数)とは異なり、順序尺度を等間隔ではなく、正規分布に従う連続値が何段階かに分けられたものと仮定して計算される。
今回の論文では、アンケートの結果が基本的に
"definitely not true" (1),
"probably not true" (2),
"don't know" (3),
"probably true" (4),
"definitely true" (5)
の5値の順序尺度なので、それらのポリコリック相関係数に基づいて主成分分析が行われている(ポリコリック相関係数行列の固有ベクトルを主成分としていると思われる)。
参考文献
[5] 小杉先生の資料
Parallel Analysis(PA), eigenvalues > 1 criterion (§2.3 etc.)
因子分析における因子数の決定方法。
以下は代表的な因子数の決定方法の例である。
- カイザー・ガットマン基準
-
相関行列の固有値の内、1以上のものの個数を因子数とする方法。
今回の論文に書かれている"eigenvalues > 1 criterion"はこれのことである。
1つの因子にしか負荷しない因子の固有値が最大1だから合理的である。
昔から統計ソフトが対応していたり、デフォルトの選択だったりしたので、よく使われていたらしい。
標本誤差があると因子数が多くなる傾向があり、あまり良い指標ではない。
- スクリーテスト
-
相関行列の固有値を大きい順にプロットし、下の方が成す線から離れた大きい固有値の数を因子数とする方法。
過去にはよく使われていたらしい。
- 平行分析(Parallel Analysis, Horn's PA)
-
元のデータと同じサイズの正規乱数行列の相関行列の固有値より大きい固有値の数を因子数とする方法。
現在最も推奨される方法の1つのようだ。
今回の論文では、因子数というか、データを説明するのに有効な主成分の数(次元圧縮後の主成分の数)を決めるのに用いられている。
- MAP(Minimum Average Partial)
-
主成分の影響を取り除いた偏相関(≒誤差の相関)の二乗和が最小になる主成分の数を因子数とするような感じの方法。
- 最尤解のカイ二乗検定
-
因子数を1から順に増やして、モデルの適合度を示すカイ二乗値が初めて有意でなくなった(p>0.05)所で止めるという方法。
因子分析のモデルを最尤法で求める場合、カイ二乗検定でモデルの適合度を調べられる。
結果がサンプルサイズによって変わるので、あまり良い指標ではないらしい。
- BIC(ベイズ情報量基準)
-
同じく最尤解の場合に使える方法で、BICが最小になる因子数を採用する方法。
特に順序尺度のデータをポリコリック相関係数で扱う場合に合理的らしい(ポリコリック相関係数がベイズ法で計算される為。参考文献[3]より)。
参考文献
[6] 因子分析における因子数決定法(堀先生の論文)
[7] Determining the Number of Factors to Retain in an Exploratory Factor
Analysis Using Comparison Data of Known Factorial Structure
[8] R: Kaiser-Guttman Criterion
Cohen's effect size of d (§3.1)
効果量(effect size)というのは統計的仮説検定において群間の差などを表す指標で、Cohen's dやHedges' gがよく用いられる。
Cohen's dの定義は、(群1の平均 - 群2の平均)÷プールされた標本標準偏差、であり、群間の平均の差が、帰無仮説における標準偏差の何倍かを示す。
p-valueとは異なり、サンプルサイズに依存しないので、p-valueが小さすぎてわかりにくい場合などにp-valueと共に示すのが有効である。
今回の論文でも、p-valueと共に示されている。
varimax rotation with Kaiser normalization (§3.2)
バリマックス回転(varimax rotation)は、主成分(因子)の解釈性を高める為の、多次元空間における主成分(因子)軸を回転する方法の1つ。主成分(因子)の負荷量が高い変数の個数を最小化するように、主成分(因子)負荷行列の各要素を2乗したものの各列の分散が最大になるように直交回転する。
Kaiser normalizationは、バリマックス回転において、全ての変数が回転後の解に等しく影響するように、主成分(因子)負荷を正規化する。
full information maximum likelihood estimation (§3.2)
欠損データを補完する方法の1つで、変数それぞれがある分布(正規分布など)に従っていると仮定して欠損部分を最尤推定する方法。FIMLと略されるらしい。
今回の論文では、"the correlation matrix was estimated using the full information maximum likelihood estimation."と、相関係数行列の推定にFIMLが用いられるように書かれている。例えばRのpsychパッケージには相関係数行列をFIMLで計算する関数があり
[10]、内部ではFIMLにEMアルゴリズムが用いられる
[11]ようなので、欠損データをFIMLで補完してから相関行列を求めるのではなく、欠損データの補完と相関行列の推定を同時に行ったものと推測した。
参考文献
[9] FIML Basic Concepts | Real Statistics Using Excel
[10] R: Find a Full Information Maximum Likelihood (FIML) correlation...
[11] Package 'lavaan'
Mann-Whitney U test (§3.4)
2群の中央値に差があるかどうかを検定する、ノンパラメトリックな手法。
2群のデータを全て合わせて小さい方から順位をつけ、群1,群2のそれぞれの順位の和をR
1,R
2とし、U
1,U
2を
U
1 = n
1n
2 + n
1(n
1+1)/2 - R
1
U
2 = n
1n
2 + n
2(n
2+1)/2 - R
2
(n
1,n
2はそれぞれ群1,群2のデータ数)とし、その小さい方を検定量Uとし、Uの確率分布からp-valueを求めるという感じの方法。
統計検定準1級の出題範囲にもある、お馴染みのウィルコクスンの順位和検定と同じ結果になるらしい。
Benjamini-Hochberg procedure, Bonferroni correction (§3.4)
多重検定を行うと誤検出率が上がってしまう問題に対処する方法。
同じ有意水準で複数の検定を行うと、実際には有意差が無くてももどれかでは有意となる確率("familywise error rate", FWER)が上がる。例えば有意水準α=0.05とすると、実際には有意差無しでも有意となってしまう(Type I errorの)確率が0.05なので、同じ有意水準で検定を3つ行ってどれかでは有意となる確率は 1-(1-0.05)
3≒0.14 となる。
Bonferroni correction(ボンフェローニ補正)は、mを検定の数として、複数の検定における有意水準を一律にα/mとする単純な方法。m個の検定のどれかが有意となる確率はαより小さくなるので、検出の基準が厳しくなる。即ち、有意なものを検出できなくなる(Type II error)確率が上がる。mが大きいほど顕著になる。
Benjamini-Hochberg procedure(BH法)は、m個のp-valueを小さい順に並べたi番目のp-valueをpiとして、pi≦(i/m)αを満たす最大のiまでのpiに対応する帰無仮説を棄却するという方法。ボンフェローニ補正の問題を解消できる。
今回の論文には、年齢の違い(中央値より大か小か)、性別の違いについてMann-WhitneyのU検定で有意差があるかどうかを調べる際に、多重検定の問題はfamilywise error rateを制御するのではなくBenjamini-Hochberg procedureでp-valueを調整することで対処している、Bonferroni correctionよりは厳しくないので偽陰性の数を下げられると書かれている。
![\begin{align}<br />
\phi_Z(t) & = E[e^{itZ}] = \int_{-\infty}^{\infty} \frac{1}{\sqrt{2\pi}} e^{-\frac{z^2}{2}} e^{itz} dz \\<br />
&= \frac{1}{\sqrt{2\pi}} \int_{-\infty}^{\infty} e^{-\frac{1}{2}((z-it)^2 + t^2)} dz \\<br />
&= \frac{1}{\sqrt{2\pi}} e^{-\frac{t^2}{2}} \int_{-\infty}^{\infty} e^{-\frac{(z-it)^2}{2}} dz \\<br />
&= e^{-\frac{t^2}{2}}<br />
\end{align}](/archives/images/clt02.png)
![\begin{align}<br />
\phi_{Z_n}(t) & = E[e^{itZ_n}] = E\left[\exp \left( it\frac{\sqrt{n}}{\sigma}\frac{1}{n}\sum_{j=1}^n (X_j-\mu) \right)\right] \\<br />
&= E\left[\prod_{j=1}^n \exp\left(it\frac{(X_j-\mu)}{\sqrt{n} \sigma} \right)\right] \\<br />
&= \left( E\left[ \exp\left(it\frac{(X_1-\mu)}{\sqrt{n} \sigma} \right)\right] \right)^n \\<br />
\end{align}](/archives/images/clt04.png)
![\begin{align}<br />
\phi_{Z_n}(t) & = \left( E\left[1 + \frac{it}{\sqrt{n}}\left(\frac{X_1-\mu}{ \sigma}\right) - \frac{t^2}{2n}\left(\frac{X_1-\mu}{ \sigma}\right)^2 - O(\frac{1}{n\sqrt{n}}) \right]\right)^n \\<br />
&= \left(1 - \frac{t^2}{2n} - O(\frac{1}{n\sqrt{n}}) \right)^n<br />
\end{align}](/archives/images/clt06.png)