15年くらい前にExcelのピボットテーブルを使ってみて以来ずっと、ピボットテーブルとは何なのかが理解できなかった。2年くらい前にも、ピボットテーブルを初心者向けに詳しく解説したITProの記事を読んで、今度こそ理解しようと意気込んで、何も見ずに演習問題を解けるようにもなったが、結局「ピボットテーブル」の意味を理解できず、ただ演習問題の解き方を丸暗記したような感じで終わってしまった。
筆者にとってピボットテーブルは、わかりそうなのにわからない、何故分からないのかがわからない、まるで眼の盲点のように、筆者の脳はそれが理解できない作りになっているかのように思えるものだった。
最近、久々にPandasを勉強する機会があって、ピボットテーブルが出てきて、また理解できなかった。しかし、何回かgroupbyの練習をした後、ふと、ピボットテーブルってgroupbyと似てるなと思い、Webで調べたらピボットテーブルはGroupByを2次元にしたようなものというような説明が見つかって、遂に理解に成功した。
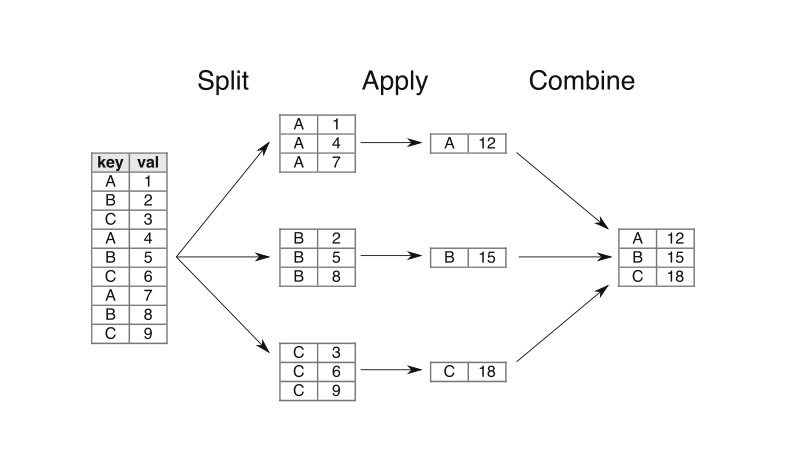
GroupByの動作は、split-apply-combineと言われるように、データをキーによって分割し、分割した単位で何らかの処理を適用し、結合して1つのデータにするものである。
次の図は、データをkey列の値によって分割し、分割された組毎に合計値を計算して1つの値に「集約(aggregate)」し、1つのデータにまとめる、というGroupByの処理の例を表している。
import pandas as pd
df = pd.DataFrame({
'key': ['A', 'B', 'C'] * 3,
'val': range(1, 10)})
print(df)
print(df.groupby('key').aggregate(sum))
key val 0 A 1 1 B 2 2 C 3 3 A 4 4 B 5 5 C 6 6 A 7 7 B 8 8 C 9
val
key
A 12
B 15
C 18
Applyは集約に限らず、単に表を変形したり、グループ毎の値を使って値を変換することなども含まれるが、グループ毎に集約するのがGroupByやピボットテーブルの醍醐味だと思うので、この記事の例では集約にしている。
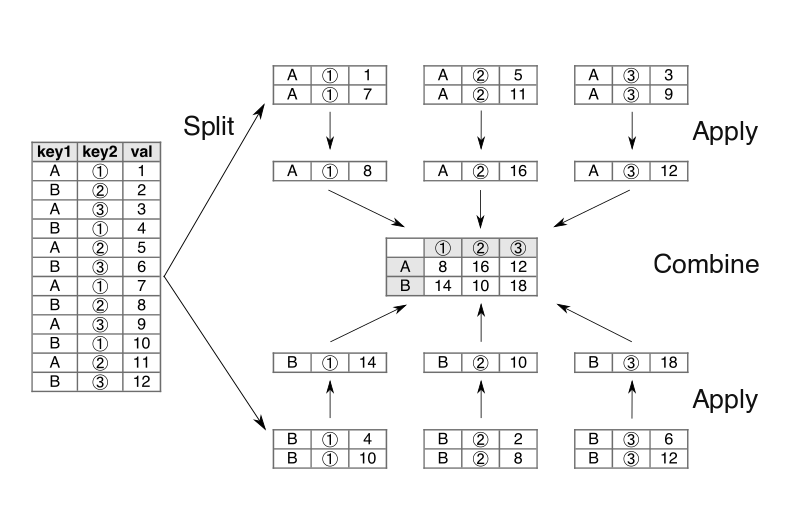
ピボットテーブルは、split-apply-combineを行方向と列方向に同時に行うものと捉えることができる。
次の図は、データをkey1列の値によって行方向に、key2列の値によって列方向に分割し、同様に分割毎に合計値に集約し、1つのデータに結合する、というピボットテーブルの処理の例を表している。
 ●コード例(pivot_tableメソッド使用)
●コード例(pivot_tableメソッド使用)
import pandas as pd
df = pd.DataFrame({
'key1': ['A', 'B'] * 6,
'key2': ['①', '②', '③'] * 4,
'val': range(1, 13)})
print(df)
print(df.pivot_table(index='key1', columns='key2', values='val', aggfunc='sum'))
key1 key2 val 0 A ① 1 1 B ② 2 2 A ③ 3 3 B ① 4 4 A ② 5 5 B ③ 6 6 A ① 7 7 B ② 8 8 A ③ 9 9 B ① 10 10 A ② 11 11 B ③ 12
key2 ① ② ③ key1 A 8 16 12 B 14 10 18
ピボットテーブルはGroupByを2次元にしたようなもの、ということを確認する為に、pivot_tableの代わりにgroupbyを2つ使って同じ結果にしてみる。
●コード例(groupbyメソッドを2つ使用)
print(df.groupby('key1').apply(lambda x: x.groupby('key2')['val'].apply(sum)))
key2 ① ② ③ key1 A 8 16 12 B 14 10 18
値を複数指定して、pivot_table()の出力の列が階層型インデックスになる場合についても、groupby()を2つ組み合わせて同じ結果になるコード例を作ってみた。
●コード例(pivot_tableメソッド使用)
import pandas as pd
df = pd.DataFrame({
'key1': ['A', 'B'] * 6,
'key2': ['①', '②', '③'] * 4,
'val1': range(1, 13),
'val2': np.linspace(0.1, 1.2, 12)})
key1 key2 val1 val2 0 A ① 1 0.1 1 B ② 2 0.2 2 A ③ 3 0.3 3 B ① 4 0.4 4 A ② 5 0.5 5 B ③ 6 0.6 6 A ① 7 0.7 7 B ② 8 0.8 8 A ③ 9 0.9 9 B ① 10 1.0 10 A ② 11 1.1 11 B ③ 12 1.2
val1 val2
key2 ① ② ③ ① ② ③
key1
A 8 16 12 0.8 1.6 1.2
B 14 10 18 1.4 1.0 1.8
print(df.groupby('key1').apply(lambda x: x.groupby('key2').apply(lambda x: x.sum()[['val1', 'val2']])).unstack())
val1 val2
key2 ① ② ③ ① ② ③
key1
A 8 16 12 0.8 1.6 1.2
B 14 10 18 1.4 1.0 1.8
コメント