筆者は今、会社でビッグデータを扱うことがあり、周囲でSQLがよく使われるようになってきた。自分では単純なクエリしか書かないが、時々他の人が書いたSQLを読む機会がある。他の人が書いたSQLも大体基本的な構文しか使ってないので、頑張れば読める。その中で唯一、よくわかってないままだったのが、ウィンドウ関数である。
筆者はあまりSQLに深入りする気が無く、こういう複雑な文法は覚える気が無いのだが、ウィンドウ関数だけは業務上避けて通れず、筆者自身も見よう見まねで書くことがあるので、この正月休みに一度きちんと理解しておこうと思った。
会社のSQLサーバーはMySQLではないが、幸い自宅のRaspberry Pi (OS buster)にインストールされているMySQL(MariaDB 10.3)は同様のウィンドウ関数をサポートしているので、これを使って勉強しながら、何かやってみることにした。
| ts | id | value |
|---|---|---|
| 2023-01-01 00:00:00 | ID_001 | 10 |
| 2023-01-01 00:00:00 | ID_002 | 0 |
| 2023-01-01 00:00:00 | ID_003 | -10 |
| 2023-01-01 00:05:00 | ID_001 | 9 |
| 2023-01-01 00:05:00 | ID_002 | -4 |
| 2023-01-01 00:05:00 | ID_003 | -9 |
| 2023-01-01 00:10:00 | ID_001 | 7 |
| 2023-01-01 00:10:00 | ID_002 | -7 |
| 2023-01-01 00:10:00 | ID_003 | -7 |
| 2023-01-01 00:15:00 | ID_001 | 4 |
| 2023-01-01 00:15:00 | ID_002 | -9 |
| 2023-01-01 00:15:00 | ID_003 | -4 |
| 2023-01-01 00:20:00 | ID_001 | 1 |
| 2023-01-01 00:20:00 | ID_002 | -10 |
| 2023-01-01 00:20:00 | ID_003 | -1 |
| ... | ... | ... |
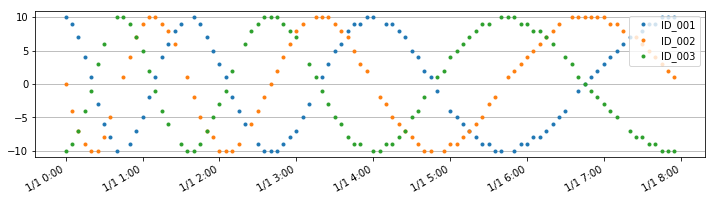
こういう時系列のデータがある時に、id毎に、直前1時間の分散が一定以上であるデータが連続する区間を抽出したいとする(テストデータ作成に用いたコードは後述)。
大体5分毎になっているが、欠損があり、12行前が1時間前とは限らないとする。
まず、各行の1時間前までの分散を計算する。
id毎に計算するのでPARTITION BY id、1時間前までのフレームなのでMySQLならORDER BY ts RANGE INTERVAL 1 HOUR PRECEDING(RANGE以降はRANGE BETWEEN INTERVAL 1 HOUR PRECEDING AND CURRENT ROWでも同じ)だがあいにくMariaDB 10.3では日付型のRANGEが未サポートのようなのでORDER BY UNIX_TIMESTAMP(ts) RANGE 3600 PRECEDINGとする。
SELECT
ts,
id,
value,
VARIANCE(value) OVER (PARTITION BY id ORDER BY UNIX_TIMESTAMP(ts) RANGE 3600 PRECEDING) AS rollvar
FROM testdata;
| ts | id | value | rollvar |
|---|---|---|---|
| 2023-01-01 00:00:00 | ID_001 | 10 | 0.0000 |
| 2023-01-01 00:05:00 | ID_001 | 9 | 0.2500 |
| 2023-01-01 00:10:00 | ID_001 | 7 | 1.5556 |
| 2023-01-01 00:15:00 | ID_001 | 4 | 5.2500 |
| 2023-01-01 00:20:00 | ID_001 | 1 | 10.9600 |
| 2023-01-01 00:25:00 | ID_001 | -3 | 20.8889 |
| 2023-01-01 00:30:00 | ID_001 | -6 | 31.8367 |
| 2023-01-01 00:35:00 | ID_001 | -8 | 41.4375 |
| 2023-01-01 00:40:00 | ID_001 | -10 | 50.4691 |
| ... | ... | ... | ... |
| 2023-01-01 07:35:00 | ID_003 | -9 | 14.0764 |
| 2023-01-01 07:40:00 | ID_003 | -9 | 11.9097 |
| 2023-01-01 07:45:00 | ID_003 | -10 | 10.9167 |
| 2023-01-01 07:50:00 | ID_003 | -10 | 9.3889 |
| 2023-01-01 07:55:00 | ID_003 | -10 | 7.5764 |
各idの最初の方は1時間分のデータが無い分散になってしまうのと、フレームが1時間の両端のタイムスタンプを含むので1時間5分の分散のようになってしまうが、今回は練習なのでこれで良しとする。
ついでに、WINDOW句(名前付きウィンドウ)を使って、同じフレームの1時間の平均も求めるようにする。
SELECT
ts,
id,
value,
AVG(value) OVER w AS rollmean,
VARIANCE(value) OVER w AS rollvar
FROM testdata
WINDOW w AS (PARTITION BY id ORDER BY UNIX_TIMESTAMP(ts) RANGE 3600 PRECEDING);
| ts | id | value | rollmean | rollvar |
|---|---|---|---|---|
| 2023-01-01 00:00:00 | ID_001 | 10 | 10.0000 | 0.0000 |
| 2023-01-01 00:05:00 | ID_001 | 9 | 9.5000 | 0.2500 |
| 2023-01-01 00:10:00 | ID_001 | 7 | 8.6667 | 1.5556 |
| 2023-01-01 00:15:00 | ID_001 | 4 | 7.5000 | 5.2500 |
| 2023-01-01 00:20:00 | ID_001 | 1 | 6.2000 | 10.9600 |
| 2023-01-01 00:25:00 | ID_001 | -3 | 4.6667 | 20.8889 |
| 2023-01-01 00:30:00 | ID_001 | -6 | 3.1429 | 31.8367 |
| 2023-01-01 00:35:00 | ID_001 | -8 | 1.7500 | 41.4375 |
| 2023-01-01 00:40:00 | ID_001 | -10 | 0.4444 | 50.4691 |
| 2023-01-01 00:50:00 | ID_001 | -9 | -0.5000 | 53.4500 |
| ... | ... | ... | ... | ... |
| 2023-01-01 07:35:00 | ID_003 | -9 | -3.5833 | 14.0764 |
| 2023-01-01 07:40:00 | ID_003 | -9 | -4.5833 | 11.9097 |
| 2023-01-01 07:45:00 | ID_003 | -10 | -5.5000 | 10.9167 |
| 2023-01-01 07:50:00 | ID_003 | -10 | -6.3333 | 9.3889 |
| 2023-01-01 07:55:00 | ID_003 | -10 | -7.0833 | 7.5764 |
次に、一例として1時間の分散が40以上の行を1とするフラグの列を付ける。 上のクエリをサブクエリとして、その結果を使えば簡単である。
WITH t1 AS (
SELECT
ts,
id,
value,
AVG(value) OVER w AS rollmean,
VARIANCE(value) OVER w AS rollvar
FROM testdata
WINDOW w AS (PARTITION BY id ORDER BY UNIX_TIMESTAMP(ts) RANGE 3600 PRECEDING)
)
SELECT *, rollvar >= 40 AS flag FROM t1;
| ts | id | value | rollmean | rollvar | flag |
|---|---|---|---|---|---|
| 2023-01-01 00:00:00 | ID_001 | 10 | 10.0000 | 0.0000 | 0 |
| 2023-01-01 00:05:00 | ID_001 | 9 | 9.5000 | 0.2500 | 0 |
| 2023-01-01 00:10:00 | ID_001 | 7 | 8.6667 | 1.5556 | 0 |
| 2023-01-01 00:15:00 | ID_001 | 4 | 7.5000 | 5.2500 | 0 |
| 2023-01-01 00:20:00 | ID_001 | 1 | 6.2000 | 10.9600 | 0 |
| 2023-01-01 00:25:00 | ID_001 | -3 | 4.6667 | 20.8889 | 0 |
| 2023-01-01 00:30:00 | ID_001 | -6 | 3.1429 | 31.8367 | 0 |
| 2023-01-01 00:35:00 | ID_001 | -8 | 1.7500 | 41.4375 | 1 |
| 2023-01-01 00:40:00 | ID_001 | -10 | 0.4444 | 50.4691 | 1 |
| 2023-01-01 00:50:00 | ID_001 | -9 | -0.5000 | 53.4500 | 1 |
| 2023-01-01 00:55:00 | ID_001 | -7 | -1.0909 | 52.0826 | 1 |
| 2023-01-01 01:00:00 | ID_001 | -5 | -1.4167 | 48.9097 | 1 |
| 2023-01-01 01:05:00 | ID_001 | -2 | -2.4167 | 37.0764 | 0 |
| 2023-01-01 01:10:00 | ID_001 | 1 | -3.0833 | 26.7431 | 0 |
| 2023-01-01 01:15:00 | ID_001 | 4 | -3.3333 | 22.3889 | 0 |
| ... | ... | ... | ... | ... | ... |
次に、上のフラグが変化する部分=フラグの値が同じ部分の先頭行を1とする列を加える。
ウィンドウ関数のLAG()を使って1つ前のデータを参照すれば容易である。
但し、LAG()は各idの1つ前が無い先頭のデータについてはNULLになり、その為flag <> lag(flag)もNULLになってしまうので、IFNULL(x, 1)で1にする。
WITH t1 AS (
SELECT
ts,
id,
value,
AVG(value) OVER w AS rollmean,
VARIANCE(value) OVER w AS rollvar
FROM testdata
WINDOW w AS (PARTITION BY id ORDER BY UNIX_TIMESTAMP(ts) RANGE 3600 PRECEDING)
), t2 AS (
SELECT *, rollvar >= 40 AS flag FROM t1
)
SELECT *, IFNULL(flag <> lag(flag) OVER (PARTITION BY id ORDER BY ts), 1) AS flagchg FROM t2;
| ts | id | value | rollmean | rollvar | flag | flagchg |
|---|---|---|---|---|---|---|
| 2023-01-01 00:00:00 | ID_001 | 10 | 10.0000 | 0.0000 | 0 | 1 |
| 2023-01-01 00:05:00 | ID_001 | 9 | 9.5000 | 0.2500 | 0 | 0 |
| 2023-01-01 00:10:00 | ID_001 | 7 | 8.6667 | 1.5556 | 0 | 0 |
| 2023-01-01 00:15:00 | ID_001 | 4 | 7.5000 | 5.2500 | 0 | 0 |
| 2023-01-01 00:20:00 | ID_001 | 1 | 6.2000 | 10.9600 | 0 | 0 |
| 2023-01-01 00:25:00 | ID_001 | -3 | 4.6667 | 20.8889 | 0 | 0 |
| 2023-01-01 00:30:00 | ID_001 | -6 | 3.1429 | 31.8367 | 0 | 0 |
| 2023-01-01 00:35:00 | ID_001 | -8 | 1.7500 | 41.4375 | 1 | 1 |
| 2023-01-01 00:40:00 | ID_001 | -10 | 0.4444 | 50.4691 | 1 | 0 |
| 2023-01-01 00:50:00 | ID_001 | -9 | -0.5000 | 53.4500 | 1 | 0 |
| 2023-01-01 00:55:00 | ID_001 | -7 | -1.0909 | 52.0826 | 1 | 0 |
| 2023-01-01 01:00:00 | ID_001 | -5 | -1.4167 | 48.9097 | 1 | 0 |
| 2023-01-01 01:05:00 | ID_001 | -2 | -2.4167 | 37.0764 | 0 | 1 |
| 2023-01-01 01:10:00 | ID_001 | 1 | -3.0833 | 26.7431 | 0 | 0 |
| 2023-01-01 01:15:00 | ID_001 | 4 | -3.3333 | 22.3889 | 0 | 0 |
| ... | ... | ... | ... | ... | ... | ... |
IFNULL(flag <> lag(flag) OVER ... , 1)の部分は、MySQL独自の<=>(NULL-safe equal)という演算子(他のSQL処理系にも大体等価なものがありそう)を使ってNOT flag <=> lag(flag) OVER ...とも書けたが、可読性に難ありと思った。
次に、フラグが変化した回数を累積し、フラグの値が同じ部分のグループ番号とする。
これもウィンドウ関数を使えば容易である。
OVER句にROWSやRANGE無しでORDER BY xxxだけを付けると、ORDER BY xxx RANGE UNBOUNDED PRECEDINGと同じ、つまりその行以前の全行がフレームになる。なお、ORDER BY xxxも付けないと、ORDER BY xxx RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWINGと同じ、つまり全行がフレームになる。
WITH t1 AS (
SELECT
ts,
id,
value,
AVG(value) OVER w AS rollmean,
VARIANCE(value) OVER w AS rollvar
FROM testdata
WINDOW w AS (PARTITION BY id ORDER BY UNIX_TIMESTAMP(ts) RANGE 3600 PRECEDING)
), t2 AS (
SELECT *, rollvar >= 40 AS flag FROM t1
), t3 AS (
SELECT *, IFNULL(flag <> lag(flag) OVER (PARTITION BY id ORDER BY ts), 1) AS flagchg FROM t2
)
SELECT *, SUM(flagchg) OVER (PARTITION BY id ORDER BY ts) AS groupnum FROM t3;
| ts | id | value | rollmean | rollvar | flag | flagchg | groupnum |
|---|---|---|---|---|---|---|---|
| 2023-01-01 00:00:00 | ID_001 | 10 | 10.0000 | 0.0000 | 0 | 1 | 1 |
| 2023-01-01 00:05:00 | ID_001 | 9 | 9.5000 | 0.2500 | 0 | 0 | 1 |
| 2023-01-01 00:10:00 | ID_001 | 7 | 8.6667 | 1.5556 | 0 | 0 | 1 |
| 2023-01-01 00:15:00 | ID_001 | 4 | 7.5000 | 5.2500 | 0 | 0 | 1 |
| 2023-01-01 00:20:00 | ID_001 | 1 | 6.2000 | 10.9600 | 0 | 0 | 1 |
| 2023-01-01 00:25:00 | ID_001 | -3 | 4.6667 | 20.8889 | 0 | 0 | 1 |
| 2023-01-01 00:30:00 | ID_001 | -6 | 3.1429 | 31.8367 | 0 | 0 | 1 |
| 2023-01-01 00:35:00 | ID_001 | -8 | 1.7500 | 41.4375 | 1 | 1 | 2 |
| 2023-01-01 00:40:00 | ID_001 | -10 | 0.4444 | 50.4691 | 1 | 0 | 2 |
| 2023-01-01 00:50:00 | ID_001 | -9 | -0.5000 | 53.4500 | 1 | 0 | 2 |
| 2023-01-01 00:55:00 | ID_001 | -7 | -1.0909 | 52.0826 | 1 | 0 | 2 |
| 2023-01-01 01:00:00 | ID_001 | -5 | -1.4167 | 48.9097 | 1 | 0 | 2 |
| 2023-01-01 01:05:00 | ID_001 | -2 | -2.4167 | 37.0764 | 0 | 1 | 3 |
| 2023-01-01 01:10:00 | ID_001 | 1 | -3.0833 | 26.7431 | 0 | 0 | 3 |
| 2023-01-01 01:15:00 | ID_001 | 4 | -3.3333 | 22.3889 | 0 | 0 | 3 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 2023-01-01 07:45:00 | ID_003 | -10 | -5.5000 | 10.9167 | 0 | 0 | 9 |
| 2023-01-01 07:50:00 | ID_003 | -10 | -6.3333 | 9.3889 | 0 | 0 | 9 |
| 2023-01-01 07:55:00 | ID_003 | -10 | -7.0833 | 7.5764 | 0 | 0 | 9 |
最後に、上のグループ番号でGROUP BYしてflag=1の行のみ出力する。
WITH t1 AS (
SELECT
ts,
id,
value,
AVG(value) OVER w AS rollmean,
VARIANCE(value) OVER w AS rollvar
FROM testdata
WINDOW w AS (PARTITION BY id ORDER BY UNIX_TIMESTAMP(ts) RANGE 3600 PRECEDING)
), t2 AS (
SELECT *, rollvar >= 40 AS flag FROM t1
), t3 AS (
SELECT *, IFNULL(flag <> lag(flag) OVER (PARTITION BY id ORDER BY ts), 1) AS flagchg FROM t2
), t4 AS (
SELECT *, SUM(flagchg) OVER (PARTITION BY id ORDER BY ts) AS groupnum FROM t3
)
SELECT
id,
MIN(ts) AS 'from(ts)',
TIMESTAMPDIFF(MINUTE, MIN(ts), MAX(ts)) AS duration,
MIN(rollvar),
MAX(rollvar),
flag
FROM t4
GROUP BY id, groupnum
HAVING flag = 1;
| id | from(ts) | duration | MIN(rollvar) | MAX(rollvar) | flag |
|---|---|---|---|---|---|
| ID_001 | 2023-01-01 00:35:00 | 25 | 41.4375 | 53.4500 | 1 |
| ID_001 | 2023-01-01 01:30:00 | 20 | 42.2431 | 50.4298 | 1 |
| ID_001 | 2023-01-01 02:35:00 | 10 | 45.4722 | 49.9167 | 1 |
| ID_001 | 2023-01-01 03:40:00 | 10 | 41.0764 | 44.6389 | 1 |
| ID_002 | 2023-01-01 01:00:00 | 25 | 41.3889 | 66.0556 | 1 |
| ID_002 | 2023-01-01 01:55:00 | 20 | 44.4722 | 60.3056 | 1 |
| ID_002 | 2023-01-01 03:05:00 | 0 | 43.8333 | 43.8333 | 1 |
| ID_003 | 2023-01-01 00:40:00 | 20 | 46.7500 | 56.8100 | 1 |
| ID_003 | 2023-01-01 01:30:00 | 20 | 41.1405 | 57.6875 | 1 |
| ID_003 | 2023-01-01 02:30:00 | 15 | 46.7431 | 53.4722 | 1 |
| ID_003 | 2023-01-01 03:40:00 | 10 | 40.5764 | 43.0833 | 1 |